Modern computer science relies on foundational concepts like
sampling
,
selection
, and
redundancy
to enable efficient data processing, maintain system resilience, and ensure accurate decision-making. Understanding these concepts is vital for professionals and students alike, whether you’re designing algorithms, building resilient systems, or analyzing large datasets. This article provides an in-depth look at each concept, supported by detailed examples, practical application steps, and guidance on accessing further resources.
Sampling in Computer Science
What is Sampling?
Sampling
in computer science refers to the process of selecting a subset (sample) of data, individuals, or items from a larger population to make inferences or perform analysis without examining the entire dataset. This approach is crucial when handling large volumes of data where full population analysis is impractical or resource-intensive
[1]
.
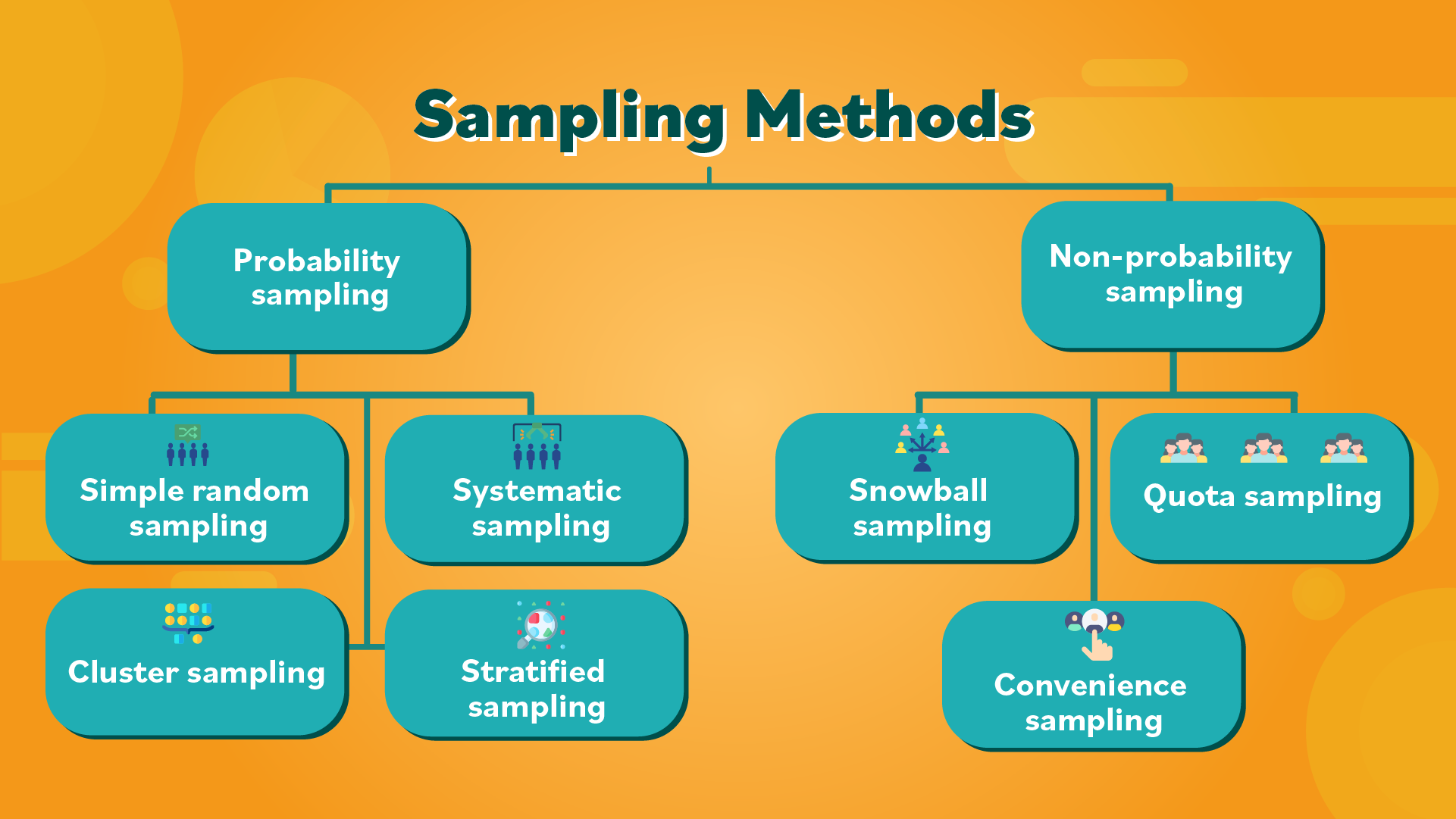
Types of Sampling Methods
Random Sampling:
Every item has an equal chance of being selected. Common in unbiased survey design and randomized algorithms.
Stratified Sampling:
The population is divided into subgroups (strata), and samples are chosen from each. Used for ensuring representation across key categories.
Systematic Sampling:
Items are selected at regular intervals from an ordered list, such as every 10th record in a database. This method is easy to implement and helps evenly distribute the sample
[4]
.
Cluster Sampling:
The population is divided into clusters, some of which are randomly selected for study. Useful for geographically dispersed data.
Convenience, Quota, Purposive, Snowball Sampling:
These non-probability techniques are used when randomization is impractical, or specific subgroups are targeted
[1]
.
Real-World Example
Suppose a cloud-based analytics platform receives millions of log entries daily. Analyzing every entry would be computationally expensive. Instead, it uses systematic sampling to select every 1,000th log entry, enabling rapid trend analysis with minimal resource overhead.
Implementation Steps
Define your target population (e.g., all entries in a database).
Choose a sampling method based on your analysis objective and available resources.
If using systematic sampling, determine the interval (
k
) by dividing the total population by desired sample size.
Randomly select a starting point within the interval and proceed by selecting every
k
th item.
Analyze the sample and extrapolate insights to the larger population, accounting for sampling bias and error
[2]
.
Potential Challenges and Solutions
Sampling may introduce bias if the chosen method is inappropriate for the population structure. To minimize bias:
Use randomized techniques when possible.
Stratify your data to ensure key groups are represented.
Increase sample size to reduce sampling error.
Alternative Approaches
In cases where sampling is infeasible or data must be preserved in its entirety (such as legal compliance), consider distributed computing frameworks (e.g., MapReduce) to process full datasets efficiently.
Selection in Computer Science
What is Selection?
Selection
in computer science covers the process of choosing specific data, items, or actions based on predefined criteria. This can refer to data selection in algorithms, conditional branching in programming, or selecting records in a database query.
Detailed Explanation
Selection mechanisms are essential for efficient data manipulation and control flow:
Algorithmic Selection:
Sorting algorithms often select a pivot or minimum/maximum value during execution (e.g., quicksort, selection sort).
Database Selection:
SQL queries use
SELECT
statements to retrieve records matching certain conditions (e.g.,
SELECT * FROM users WHERE age > 30
).
Conditional Logic:
Programming languages implement selection through
if
,
else
, and
switch
constructs, enabling branching based on runtime conditions.
Real-World Example
Consider a recommendation engine that selects the top 5 products for a user based on their browsing history, purchase patterns, and product ratings. The selection logic combines data filtering, sorting, and conditional rules to deliver personalized results.
Source: tffn.net
Implementation Steps
Define selection criteria based on the problem requirements (e.g., filter by attribute, range, or condition).
Test and validate the selection process to ensure it consistently returns desired results.
Optimize for performance, especially when handling large datasets or complex selection logic.
Potential Challenges and Solutions
Selection processes can become inefficient if criteria are complex or poorly indexed. To address this:
Source: computerscience.gcse.guru
Use indexing in databases to speed up record selection.
Precompute or cache frequently used selection results.
Refactor code to simplify and streamline selection conditions.
Alternative Approaches
For advanced scenarios, consider machine learning-based selection (e.g., clustering, classification) to automate decision-making when explicit criteria are hard to define.
Redundancy in Computer Science
What is Redundancy?
Redundancy
involves introducing extra data, components, or pathways into a system to enhance reliability, prevent data loss, or ensure availability in the event of failure. In computer science, redundancy is a key principle in systems design, networking, and data storage.
Detailed Explanation
Redundancy is implemented in several forms:
Data Redundancy:
Storing duplicate copies of data across different locations (e.g., RAID storage, cloud backups) to guard against data loss.
Hardware Redundancy:
Incorporating spare components (e.g., redundant power supplies, failover servers) to maintain operations during hardware failure.
Network Redundancy:
Using multiple network paths or connections to prevent loss of connectivity if a link fails.
Real-World Example
Mission-critical applications such as banking systems utilize redundant data centers and replication to ensure continuous service even if one facility is compromised. Similarly, cloud services often use redundant servers and storage to guarantee high availability.
Implementation Steps
Identify system components or data that are critical for operation.
Implement redundancy solutions, configuring automatic failover and regular integrity checks.
Test redundancy by simulating failures to ensure seamless recovery and minimal downtime.
Maintain and update redundancy systems to address evolving threats and requirements.
Potential Challenges and Solutions
Redundancy can increase costs and complexity. To maximize value:
Balance redundancy level against budget and risk tolerance.
Regularly audit redundant systems to eliminate unnecessary duplication.
Automate monitoring and failover procedures where possible.
Alternative Approaches
Some systems may use error correction codes or distributed consensus algorithms as alternatives or supplements to traditional redundancy for data protection and system reliability.
How to Access and Apply These Concepts
If you are looking to apply sampling, selection, or redundancy techniques in your own projects:
For data analysis, most modern programming languages (Python, R, SQL) offer built-in libraries and functions for sampling and selection. Documentation and tutorials are available on official language websites and community forums.
To implement redundancy, consult your system or cloud provider’s official documentation for guidance on configuring backups, failover, and high-availability solutions. For enterprise-grade requirements, consider contacting vendors or certified consultants for hands-on support.
When in doubt about best practices, search for terms like “probability sampling techniques in data science,” “SQL selection best practices,” or “redundant storage configuration” using reputable sources such as university websites, industry whitepapers, or documentation from major technology providers.
If you require compliance with specific industry or government standards (such as HIPAA for healthcare or PCI DSS for payments), always consult the official regulatory agency for detailed requirements.
Summary and Key Takeaways
Mastering
sampling
,
selection
, and
redundancy
is foundational for building efficient, reliable, and scalable computer systems. By understanding the underlying principles, choosing appropriate methods, and following best practices, you can enhance performance, data integrity, and resilience in your computing projects. For further study, leverage official documentation, academic resources, and industry case studies tailored to your application domain.